DeepSeek V3.2 do kodowania: dobra jakość za ułamek ceny
DeepSeek V3.2 oferuje mocne kodowanie przy cenach API, które rozbrajają konkurencję. Sprawdzamy, gdzie realnie się nadaje i ile płacisz w złotówkach.
DeepSeek V3.2 to dziś jedna z najciekawszych ofert cena/jakość w kodowaniu. Za milion tokenów wejściowych płacisz grosze, a model bez większego zająknięcia ogarnia typowe zadania webowe, skrypty i refaktory w obrębie jednego czy dwóch plików. Dla osoby, która dopiero uczy się vibe codingu i nie chce od razu przepalać budżetu na najdroższych modelach, to naturalny punkt startu.
Ile to realnie kosztuje
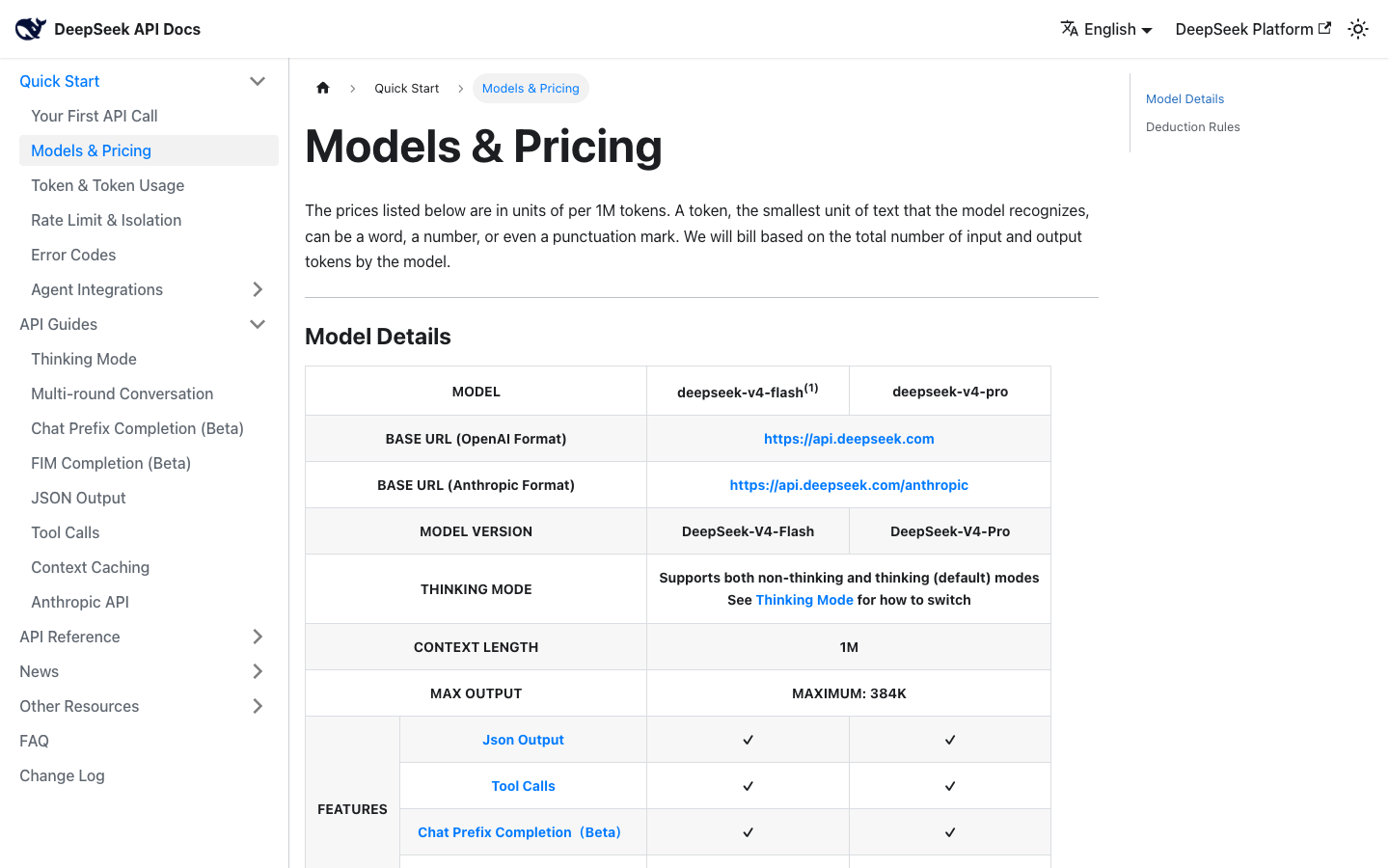
Zacznijmy od liczb, bo tu jest cała sól. Według danych Artificial Analysis (pobrane 2 lipca 2026) wariant rozumujący DeepSeek V3.2 kosztuje 0,30 USD za milion tokenów wejściowych i 0,45 USD za milion wyjściowych. Po kursie ok. 3,65 zł/USD to odpowiednio jakieś 1,10 zł i 1,64 zł za milion tokenów. Dla porównania Claude Opus 4.8 w tych samych danych to 5 USD wejście i 25 USD wyjście, czyli rząd wielkości drożej na wyjściu.
DeepSeek dobił do tego pułapu, tnąc ceny agresywnie. VentureBeat opisywał, że eksperymentalna wersja V3.2 obcięła cennik API o połowę, schodząc poniżej 3 centów za milion tokenów wejściowych na trafieniach w cache. To nie przypadek. Za oszczędnościami stoi mechanizm DeepSeek Sparse Attention, który redukuje koszt liczenia przy długim oknie kontekstu (model obsługuje ok. 131 tys. tokenów).
Jak wypada w kodowaniu
Cena bez jakości byłaby pułapką, więc sprawdźmy drugą stronę. Na benchmarku SWE Multilingual DeepSeek V3.2 uzyskał 70,2%, wyraźnie wyprzedzając 55,3% GPT-5 w tym samym teście. W rankingu programowania zawodowego Codeforces model osiągnął rating rzędu 2701, co plasuje go w górnej półce. Na LiveCodeBench zanotował 83,3%, czyli tuż za czołówką (GPT-5 miało 84,5%, a Gemini 3 Pro 90,7%).
Wniosek jest zdroworozsądkowy. W najtrudniejszych, wieloplikowych refaktorach i długich zadaniach agentowych wciąż wygrywają najdrożsi liderzy. Ale w codziennej robocie, czyli dopisaniu endpointu, poprawieniu komponentu, napisaniu skryptu migracyjnego, różnica jakości jest na tyle mała, że przy takiej cenie trudno ją uzasadnić dopłatą.
Dla kogo to dobry wybór
DeepSeek V3.2 sprawdzi się w kilku konkretnych sytuacjach. Uczysz się i puszczasz dużo eksperymentów, więc chcesz, żeby każdy nieudany prompt kosztował ułamek grosza. Budujesz narzędzie, które generuje sporo tokenów w tle (np. streszcza, klasyfikuje, przepisuje), a rachunek na drogim modelu urósłby lawinowo. Albo po prostu robisz prototyp i wolisz przepalić budżet na iteracje niż na jeden „idealny“ strzał.
Są też granice. Jeśli pracujesz nad dużym repo z zależnościami rozsianymi po wielu plikach, model częściej się gubi niż topowy Claude Opus 4.8. Do zadań, gdzie błąd jest kosztowny (kod produkcyjny, logika płatności, bezpieczeństwo), traktuj DeepSeek jako pierwszy szkic, który sam sprawdzasz, a nie jako wyrocznię.
Skąd te niskie ceny
Warto rozumieć, dlaczego DeepSeek może być tak tani, bo to nie jest promocja na chwilę. Model korzysta z mechanizmu DeepSeek Sparse Attention, który upraszcza najbardziej kosztowną część liczenia przy długich tekstach. W skrócie: zamiast za każdym razem porównywać każdy fragment z każdym innym, model skupia się na tym, co istotne. Efekt to niższy koszt zarówno treningu, jak i codziennego użycia, przy zachowaniu jakości w długim oknie kontekstu.
Do tego dochodzi bardzo agresywna polityka cache. Trafienie w cache (czyli powtórne użycie tego samego kontekstu) potrafi kosztować grosze za milion tokenów, więc przy pracy, w której często wracasz do tych samych plików, realny rachunek bywa jeszcze niższy niż stawka podstawowa. Dla vibe codingu, gdzie iterujesz na tym samym projekcie w kółko, to zauważalna oszczędność.
DeepSeek na tle innych tanich modeli
DeepSeek nie jest jedyną tanią opcją i warto go zestawić z konkurencją, zanim wybierzesz. Qwen3-Coder-Next stawia na szybkość generowania, a GLM-5.2 na duże okno kontekstu i mocne wyniki w zadaniach agentowych. Każdy z nich celuje w nieco inny punkt na osi cena, jakość i prędkość. Zdrowe podejście to nie szukanie „najlepszego modelu w ogóle“, tylko dopasowanie do konkretnego zadania i budżetu.
Jak to przetestować bez ryzyka
Najprostsza ścieżka: weź jeden realny task, który już umiesz ocenić, i puść go na DeepSeek oraz na modelu, którego zwykle używasz. Porównaj nie tylko efekt, ale też ile tokenów każdy z nich zużył i ile prób potrzebowałeś. Dopiero to daje uczciwy obraz kosztu, bo tańszy model, który wymaga trzech podejść, potrafi wyjść drożej niż droższy za pierwszym razem.
Jeśli chcesz oszacować rachunek przy własnym wolumenie, wrzuć ceny do naszego kalkulatora kosztów API. Pozycję DeepSeek V3.2 na tle innych modeli, z aktualnymi benchmarkami i cenami, znajdziesz w karcie modelu. Krótko: to koń roboczy do dużej części codziennej pracy, a nie mistrz od najcięższych zadań. I dokładnie tak warto go traktować.
Opanuj AI‑coding w 5 minut. W każdy poniedziałek.
Konkretne premiery, analizy cen i jeden trik, który przyspieszy Twoją pracę. Po polsku, bez żargonu, prosto na maila.