Token
Token to najmniejszy kawałek tekstu, na jaki model językowy dzieli to, co czyta i pisze. Token bywa całym krótkim słowem, jego fragmentem, znakiem interpunkcyjnym albo spacją. To właśnie w tokenach mierzy się długość rozmowy i nalicza koszty korzystania z API.
W uproszczeniu: model nie widzi liter ani słów tak jak my. Widzi ciąg tokenów i na ich podstawie przewiduje kolejne. Dlatego token to podstawowa „waluta“ pracy z AI.
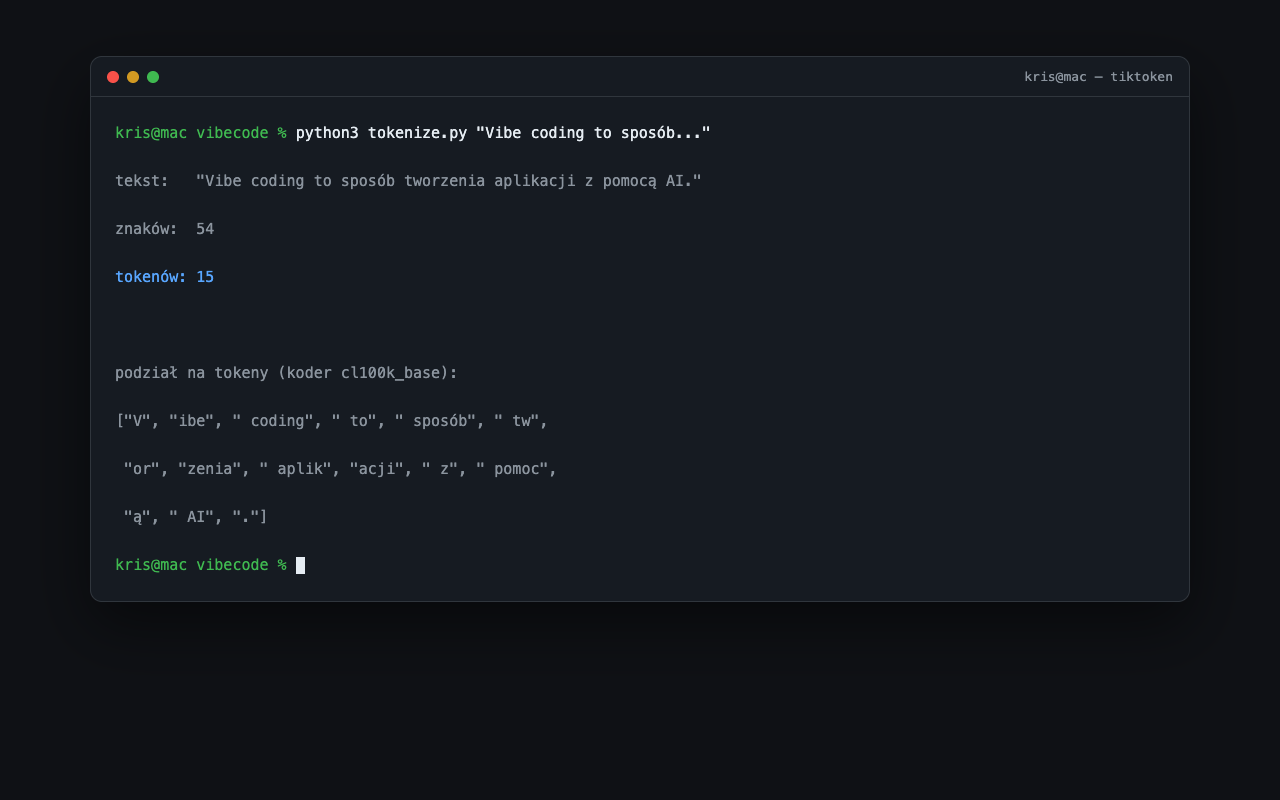
Ile to jest jeden token
Praktyczna zasada dla języka angielskiego: jeden token to średnio około czterech znaków, czyli mniej więcej trzy tokeny na dwa słowa. Polski dzieli się nieco gorzej, bo modele były trenowane głównie na angielskim, więc te same treści po polsku potrafią zająć więcej tokenów. Krótkie, popularne słowo („kot“) często jest jednym tokenem, a długie lub rzadkie („nieprzewidywalność“) rozpada się na kilka.
Liczą się oba kierunki. Tokeny wejściowe to wszystko, co wysyłasz do modelu (prompt, pliki, historia rozmowy). Tokeny wyjściowe to odpowiedź, którą model generuje. W cennikach API zwykle płacisz osobno za jedne i drugie, a wyjściowe bywają kilka razy droższe.
Dlaczego tokeny są ważne w vibe codingu
Dwie rzeczy zależą wprost od tokenów. Po pierwsze koszt. Rachunek za pracę z modelem to liczba tokenów pomnożona przez stawkę za milion. Kiedy wrzucasz agentowi całe repozytorium do każdego pytania, zużycie rośnie lawinowo, a z nim rachunek. Dlatego opłaca się podawać tylko to, co potrzebne.
Po drugie limit. Model przyjmuje naraz ograniczoną liczbę tokenów, mieszczącą się w jego oknie kontekstu. Gdy rozmowa albo projekt są za duże, część treści trzeba przyciąć, streścić albo podzielić na etapy. Świadomość, ile tokenów zjada Twoja praca, przekłada się wprost na niższe koszty i mniej problemów z limitami.
Jeśli chcesz zobaczyć na własne oczy, jak tekst rozbija się na tokeny, sprawdź nasz tokenizer online albo przelicz koszt w kalkulatorze kosztów API.
Częste nieporozumienia
Pierwsze: token to nie to samo co słowo ani znak. Jedno słowo może być jednym tokenem albo kilkoma, zależnie od jego długości i popularności. Dlatego „1000 słów“ i „1000 tokenów“ to nie ta sama miara.
Drugie: spacje i znaki interpunkcyjne też się liczą. Puste linie, wcięcia w kodzie i formatowanie zwiększają liczbę tokenów, nawet jeśli nie niosą treści.
Trzecie: różne modele dzielą tekst na tokeny nieco inaczej. Ta sama wiadomość może mieć trochę inną liczbę tokenów w zależności od modelu, więc porównując koszty, patrz na stawkę i na realne zużycie, a nie tylko na długość tekstu.
Prosty przykład na wyczucie skali
Załóżmy, że pracujesz z modelem po 4 zł za milion tokenów wyjściowych. Wygenerowanie tekstu długości tego hasła to rząd kilkuset tokenów, czyli ułamek grosza. Ale gdy agent przez godzinę czyta pliki, generuje kod i sam się poprawia, potrafi zużyć setki tysięcy, a nawet miliony tokenów. Wtedy te „grosze za milion“ składają się w konkretną kwotę.
Dlatego świadomość tokenów to nie akademicka ciekawostka, tylko praktyczna umiejętność panowania nad rachunkiem. Dwa nawyki pomagają najbardziej: podawaj tylko potrzebny kontekst i wybieraj model dopasowany do zadania, zamiast domyślnie sięgać po najdroższy.
W skrócie
Token to podstawowa jednostka, w której model liczy tekst, a Ty płacisz. Im lepiej rozumiesz, co zjada tokeny, tym łatwiej trzymać koszty i limity pod kontrolą.